publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2025
-
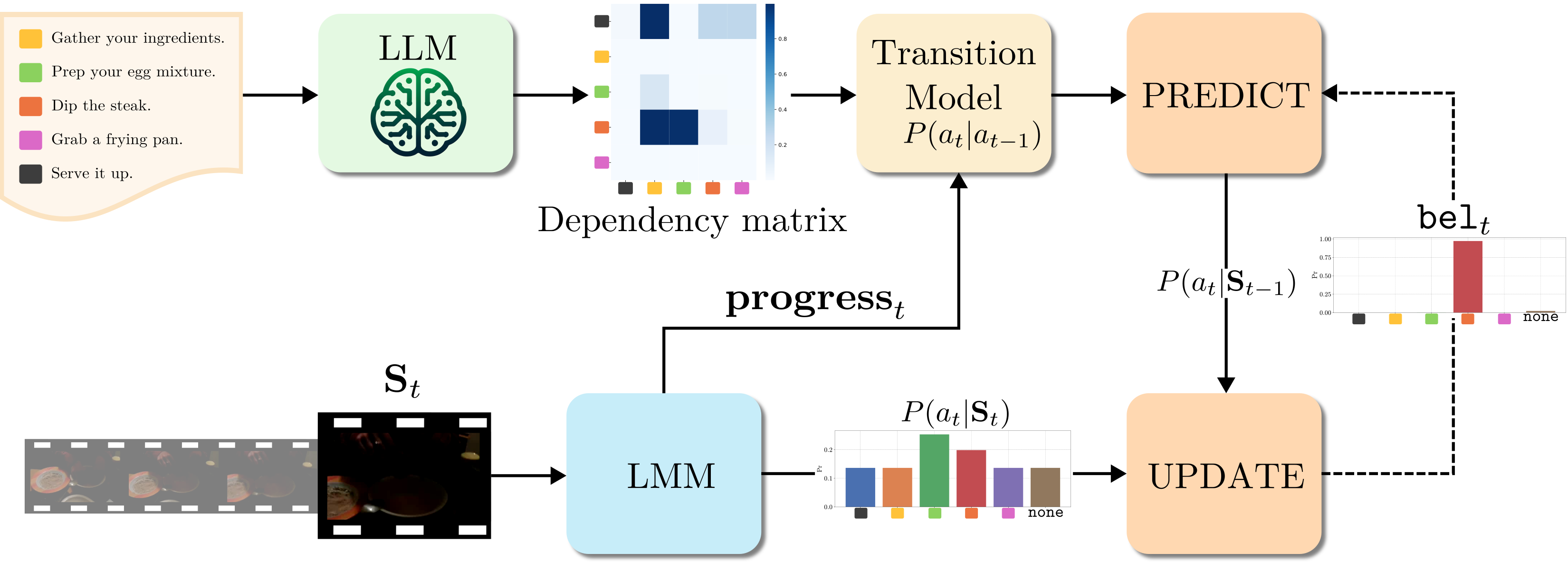 Training-free Online Video Step GroundingLuca Zanella, Massimiliano Mancini, Yiming Wang , and 2 more authorsarXiv preprint arXiv:2510.16989, 2025
Training-free Online Video Step GroundingLuca Zanella, Massimiliano Mancini, Yiming Wang , and 2 more authorsarXiv preprint arXiv:2510.16989, 2025Given a task and a set of steps composing it, Video Step Grounding (VSG) aims to detect which steps are performed in a video. Standard approaches for this task require a labeled training set (e.g., with step-level annotations or narrations), which may be costly to collect. Moreover, they process the full video offline, limiting their applications for scenarios requiring online decisions. Thus, in this work, we explore how to perform VSG online and without training. We achieve this by exploiting the zero-shot capabilities of recent Large Multimodal Models (LMMs). In particular, we use LMMs to predict the step associated with a restricted set of frames, without access to the whole video. We show that this online strategy without task-specific tuning outperforms offline and training-based models. Motivated by this finding, we develop Bayesian Grounding with Large Multimodal Models (BaGLM), further injecting knowledge of past frames into the LMM-based predictions. BaGLM exploits Bayesian filtering principles, modeling step transitions via (i) a dependency matrix extracted through large language models and (ii) an estimation of step progress. Experiments on three datasets show superior performance of BaGLM over state-of-the-art training-based offline methods.
@article{zanella2025training, title = {Training-free Online Video Step Grounding}, author = {Zanella, Luca and Mancini, Massimiliano and Wang, Yiming and Tonioni, Alessio and Ricci, Elisa}, journal = {arXiv preprint arXiv:2510.16989}, year = {2025}, } -
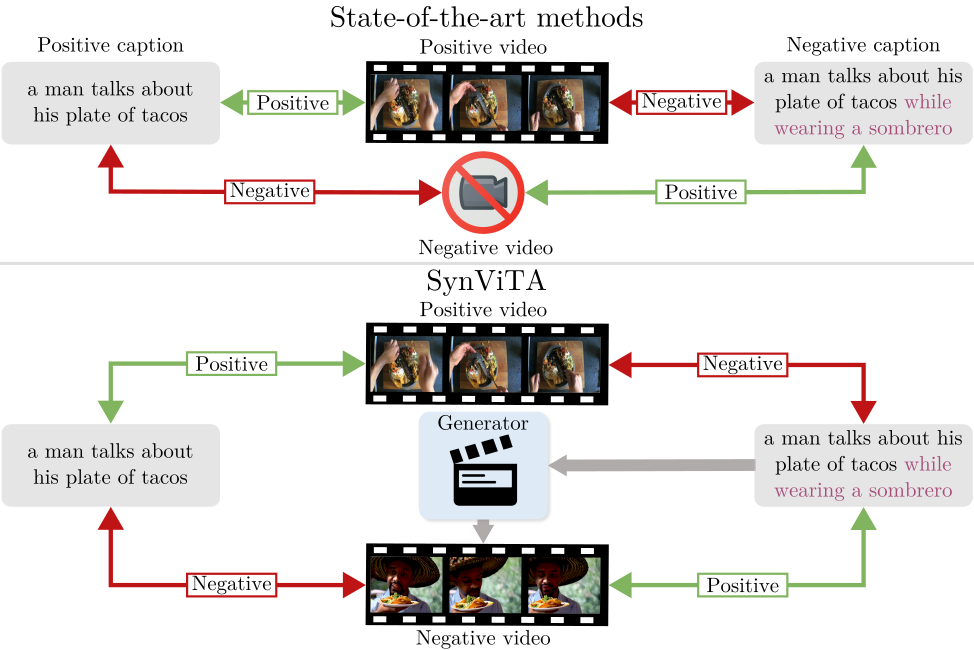 Can Text-to-Video Generation help Video-Language Alignment?Luca Zanella, Massimiliano Mancini, Willi Menapace , and 3 more authorsIn Proceedings of the Computer Vision and Pattern Recognition Conference , 2025
Can Text-to-Video Generation help Video-Language Alignment?Luca Zanella, Massimiliano Mancini, Willi Menapace , and 3 more authorsIn Proceedings of the Computer Vision and Pattern Recognition Conference , 2025Recent video-language alignment models are trained on sets of videos, each with an associated positive caption and a negative caption generated by large language models. A problem with this procedure is that negative captions may introduce linguistic biases, i.e., concepts are seen only as negatives and never associated with a video. While a solution would be to collect videos for the negative captions, existing databases lack the fine-grained variations needed to cover all possible negatives. In this work, we study whether synthetic videos can help to overcome this issue. Our preliminary analysis with multiple generators shows that, while promising on some tasks, synthetic videos harm the performance of the model on others. We hypothesize this issue is linked to noise (semantic and visual) in the generated videos and develop a method, SynViTA, that accounts for those. SynViTA dynamically weights the contribution of each synthetic video based on how similar its target caption is w.r.t. the real counterpart. Moreover, a semantic consistency loss makes the model focus on fine-grained differences across captions, rather than differences in video appearance. Experiments show that, on average, SynViTA improves over existing methods on VideoCon test sets and SSv2-Temporal, SSv2-Events, and ATP-Hard benchmarks, being a first promising step for using synthetic videos when learning video-language models.
@inproceedings{zanella2025can, title = {Can Text-to-Video Generation help Video-Language Alignment?}, author = {Zanella, Luca and Mancini, Massimiliano and Menapace, Willi and Tulyakov, Sergey and Wang, Yiming and Ricci, Elisa}, booktitle = {Proceedings of the Computer Vision and Pattern Recognition Conference}, pages = {24097--24107}, year = {2025}, }


2024
-
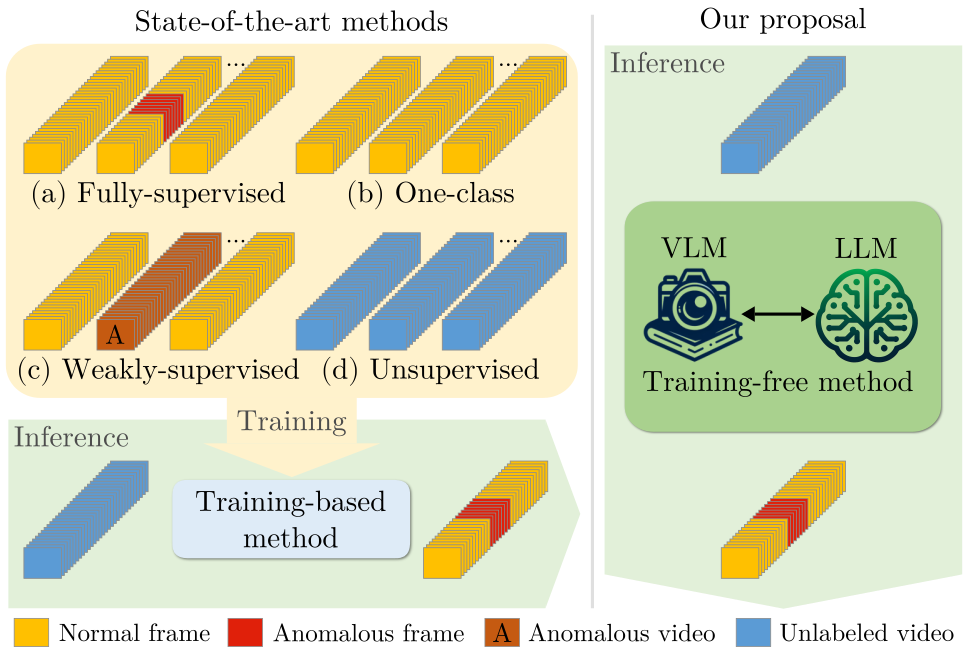 Harnessing Large Language Models for Training-free Video Anomaly DetectionLuca Zanella, Willi Menapace, Massimiliano Mancini , and 2 more authorsIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2024
Harnessing Large Language Models for Training-free Video Anomaly DetectionLuca Zanella, Willi Menapace, Massimiliano Mancini , and 2 more authorsIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2024Video anomaly detection (VAD) aims to temporally locate abnormal events in a video. Existing works mostly rely on training deep models to learn the distribution of normality with either video-level supervision, one-class supervision, or in an unsupervised setting. Training-based methods are prone to be domain-specific, thus being costly for practi- cal deployment as any domain change will involve data collection and model training. In this paper, we radically depart from previous efforts and propose LAnguage-based VAD (LAVAD), a method tackling VAD in a novel, training- free paradigm, exploiting the capabilities of pre-trained large language models (LLMs) and existing vision-language models (VLMs). We leverage VLM-based captioning models to generate textual descriptions for each frame of any test video. With the textual scene description, we then devise a prompting mechanism to unlock the capability of LLMs in terms of temporal aggregation and anomaly score estimation, turning LLMs into an effective video anomaly detector. We further leverage modality-aligned VLMs and propose effec- tive techniques based on cross-modal similarity for cleaning noisy captions and refining the LLM-based anomaly scores. We evaluate LAVAD on two large datasets featuring real- world surveillance scenarios (UCF-Crime and XD-Violence), showing that it outperforms both unsupervised and one-class methods without requiring any training or data collection.
@inproceedings{zanella2024harnessing, title = {Harnessing Large Language Models for Training-free Video Anomaly Detection}, author = {Zanella, Luca and Menapace, Willi and Mancini, Massimiliano and Wang, Yiming and Ricci, Elisa}, booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, pages = {18527--18536}, year = {2024}, } -
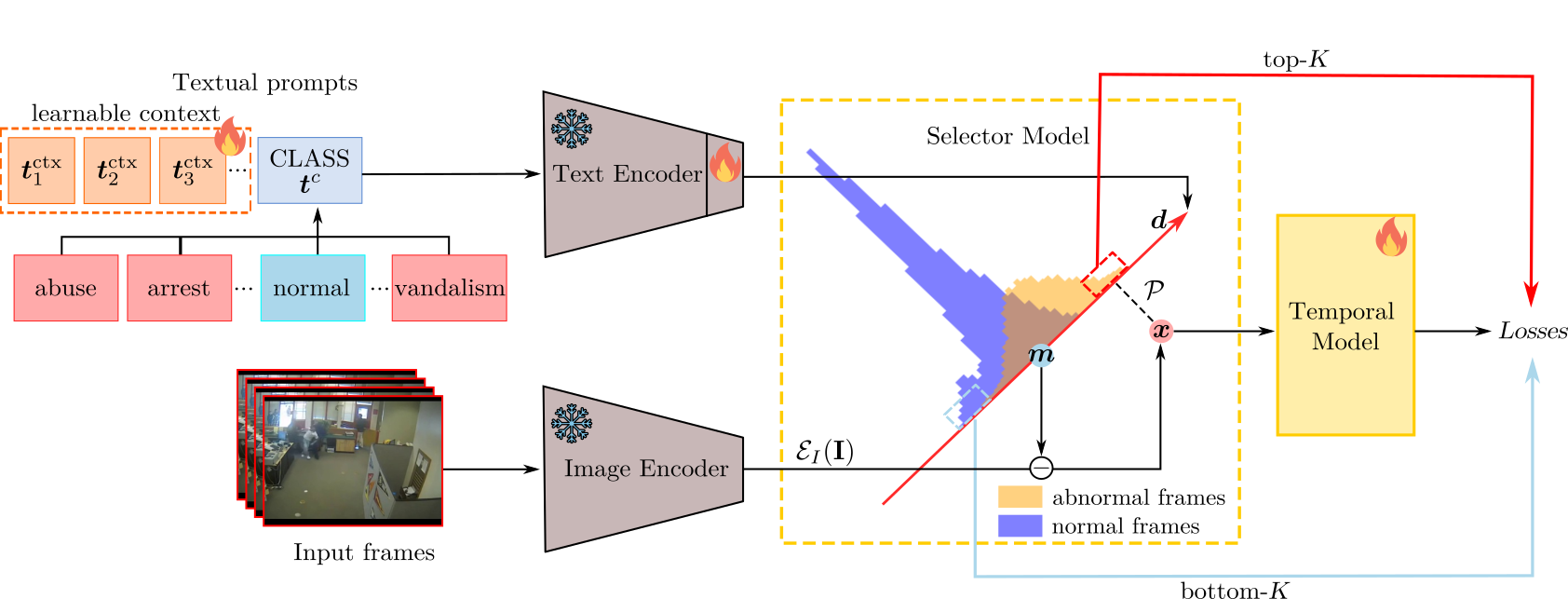 Delving into clip latent space for video anomaly recognitionLuca Zanella, Benedetta Liberatori, Willi Menapace , and 3 more authorsComputer Vision and Image Understanding, 2024
Delving into clip latent space for video anomaly recognitionLuca Zanella, Benedetta Liberatori, Willi Menapace , and 3 more authorsComputer Vision and Image Understanding, 2024We tackle the complex problem of detecting and recognising anomalies in surveillance videos at the frame level, utilising only video-level supervision. We introduce the novel method AnomalyCLIP, the first to combine Large Language and Vision (LLV) models, such as CLIP, with multiple instance learning for joint video anomaly detection and classification. Our approach specifically involves ma- nipulating the latent CLIP feature space to identify the normal event subspace, which in turn allows us to effectively learn text-driven directions for abnormal events. When anomalous frames are pro- jected onto these directions, they exhibit a large feature magnitude if they belong to a particular class. We also introduce a computationally efficient Transformer architecture to model short- and long-term temporal dependencies between frames, ultimately producing the final anomaly score and class pre- diction probabilities. We compare AnomalyCLIP against state-of-the-art methods considering three major anomaly detection benchmarks, i.e. ShanghaiTech, UCF-Crime, and XD-Violence, and empirically show that it outperforms baselines in recognising video anomalies.
@article{zanella2024delving, title = {Delving into clip latent space for video anomaly recognition}, author = {Zanella, Luca and Liberatori, Benedetta and Menapace, Willi and Poiesi, Fabio and Wang, Yiming and Ricci, Elisa}, journal = {Computer Vision and Image Understanding}, volume = {249}, pages = {104163}, year = {2024}, publisher = {Elsevier}, }


2023
-
 Confmix: Unsupervised domain adaptation for object detection via confidence-based mixingGiulio Mattolin, Luca Zanella, Elisa Ricci , and 1 more authorIn Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , 2023
Confmix: Unsupervised domain adaptation for object detection via confidence-based mixingGiulio Mattolin, Luca Zanella, Elisa Ricci , and 1 more authorIn Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , 2023Unsupervised Domain Adaptation (UDA) for object detection aims to adapt a model trained on a source domain to detect instances from a new target domain for which annotations are not available. Different from traditional approaches, we propose ConfMix, the first method that introduces a sample mixing strategy based on region-level detection confidence for adaptive object detector learning. We mix the local region of the target sample that corresponds to the most confident pseudo detections with a source image, and apply an additional consistency loss term to gradually adapt towards the target data distribution. In order to robustly define a confidence score for a region, we exploit the confidence score per pseudo detection that accounts for both the detector-dependent confidence and the bounding box uncertainty. Moreover, we propose a novel pseudo labelling scheme that progressively filters the pseudo target detections using the confidence metric that varies from a loose to strict manner along the training. We perform extensive experiments with three datasets, achieving state-of-the-art performance in two of them and approaching the supervised target model performance in the other.
@inproceedings{mattolin2023confmix, title = {Confmix: Unsupervised domain adaptation for object detection via confidence-based mixing}, author = {Mattolin, Giulio and Zanella, Luca and Ricci, Elisa and Wang, Yiming}, booktitle = {Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision}, pages = {423--433}, year = {2023}, }

2022
-
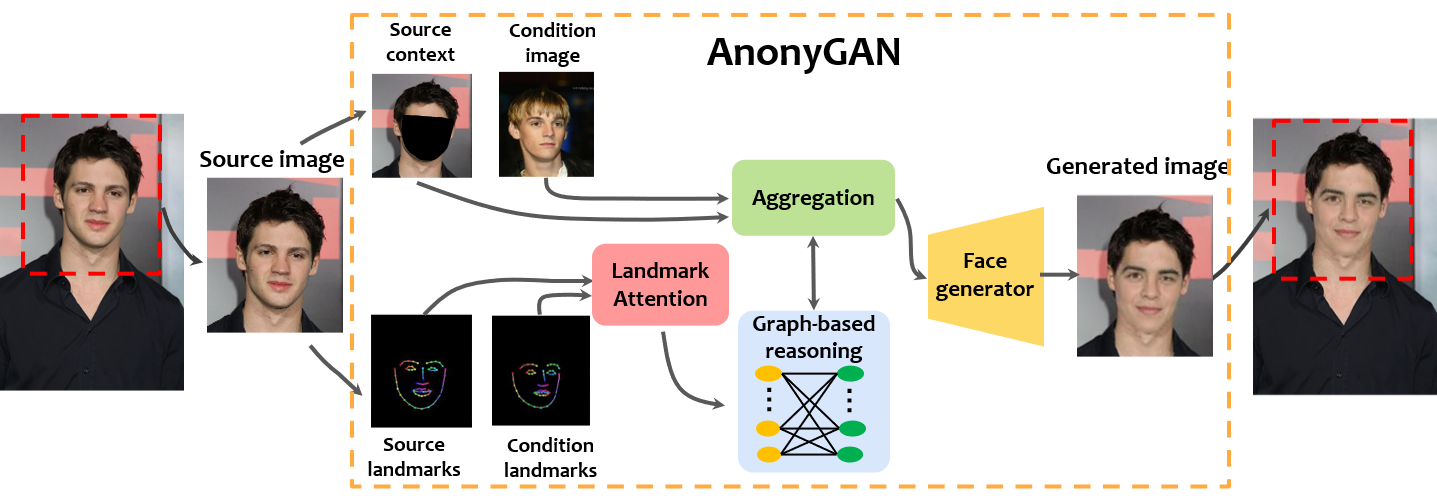 Graph-based generative face anonymisation with pose preservationNicola Dall’Asen, Yiming Wang, Hao Tang , and 2 more authorsIn International Conference on Image Analysis and Processing , 2022
Graph-based generative face anonymisation with pose preservationNicola Dall’Asen, Yiming Wang, Hao Tang , and 2 more authorsIn International Conference on Image Analysis and Processing , 2022We propose AnonyGAN, a GAN-based solution for face anonymisation which replaces the visual information corresponding to a source identity with a condition identity provided as any single image. With the goal to maintain the geometric attributes of the source face, i.e., the facial pose and expression, and to promote more natural face generation, we propose to exploit a Bipartite Graph to explicitly model the relations between the facial landmarks of the source identity and the ones of the condition identity through a deep model. We further propose a landmark attention model to relax the manual selection of facial landmarks, allowing the network to weight the landmarks for the best visual naturalness and pose preservation. Finally, to facilitate the appearance learning, we propose a hybrid training strategy to address the challenge caused by the lack of direct pixel-level supervision. We evaluate our method and its variants on two public datasets, CelebA and LFW, in terms of visual naturalness, facial pose preservation and of its impacts on face detection and re-identification. We prove that AnonyGAN significantly outperforms the state-of-the-art methods in terms of visual naturalness, face detection and pose preservation.
@inproceedings{dall2022graph, title = {Graph-based generative face anonymisation with pose preservation}, author = {Dall’Asen, Nicola and Wang, Yiming and Tang, Hao and Zanella, Luca and Ricci, Elisa}, booktitle = {International Conference on Image Analysis and Processing}, pages = {503--515}, year = {2022}, organization = {Springer}, }
